ICS Chapter III-4
CSAPP NOTE CHAP III-4
Chap 3.4 C语言的机器级表示#
数值类型和运算的机器级表示#
C语言中的整数#
- 有符号数:
intshortlong - 无符号数:
unsigned intunsigned shortunsigned long - C 语言标准规定了各类型最小取值范围,int 型至少为 16 位,取值范围为 -32768 - 32767,虽然现代编译器都是 2147483647 这个标准
- 在一个数值的后面加一个
u或者U来表示无符号数 - 运算中同时有无符号和有符号整数,按无符号整数计算
例题 1 假定以下关系表达式在 32 位用补码表示的机器上执行,结果是什么?
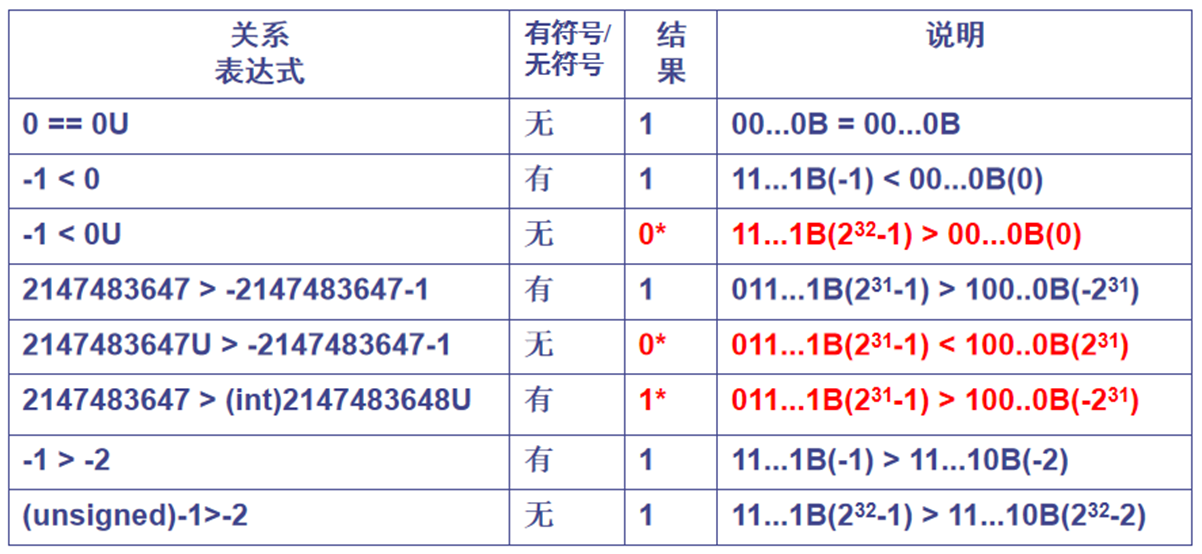
例题 2 回答以下三个问题:
-
在有些32位系统上,C表达式-2147483648 < 2147483647的执行结果为false。Why?
在 ISO C90 标准下 ,-2147483648 为 unsigned int 型,因此 “-2147483648 < 2147483647” 按无符号数比较,10……0B 比 01……1B 大,结果为 false。
在 ISO C99 标准下,2147483648 为 long long 型,因此 “-2147483648 < 2147483647” 按带符号整数比较,10……0B 比 01……1B 小,结果为 true。
-
若定义变量 “int i=-2147483648;”,则 “i < 2147483647” 的执行结果为 true。Why?
i < 2147483647 按 int 型数比较,结果为 true。
-
如果将表达式写成“-2147483647-1 < 2147483647”,则结果会怎样呢?Why?
-2147483647-1 < 2147483647 按 int 型比较,结果为 true。
例题 3 判断以下函数结果
#include <stdio.h>
void main()
{
short x;
unsigned short y;
x= -1; // x=65535
y= -1; // y=65535
printf("%d %d\n", x, y);
}
// Output -1 65535查看相关的汇编代码可知:
11b9: 66 c7 45 f4 ff ff movw $0xffff,-0xc(%ebp) # x = -1
11bf: 66 c7 45 f6 ff ff movw $0xffff,-0xa(%ebp) # y = -1
11c5: 0f b7 4d f6 movzwl -0xa(%ebp),%ecx # printf 的 %d 解读 y
11c9: 0f bf 55 f4 movswl -0xc(%ebp),%edx # printf 的 %d 解读 x例题 4 判断以下函数结果
#include <stdio.h>
int main() {
short x;
unsigned short y;
x = -1;
y = -1;
if(x > 0) printf("%d positive\n", x);
if(y > 0) printf("%d positive\n", y);
}
// Output 65535 positive查看相关的汇编代码可知:
11ba: 66 c7 45 f4 ff ff movw $0xffff,-0xc(%ebp)
11c0: 66 c7 45 f6 ff ff movw $0xffff,-0xa(%ebp)
11c6: 66 83 7d f4 00 cmpw $0x0,-0xc(%ebp)
11cb: 7e 17 jle 11e4 <main+0x47>
# ...
11e4: 66 83 7d f6 00 cmpw $0x0,-0xa(%ebp)
11e9: 74 17 je 1202 <main+0x65> # 无符号数只要不是 0 就大于 0C 语言中的浮点数#
- 类型:
doublefloat long double随编译器和处理器不同而变化,IA-32 中是 80 位int的有效位数是 32 位,而float的有效位数是 23 位,转换的时候会有精度丢失,转换为double则不会丢失- 浮点数转化为整数的时候可能会溢出或舍入,小数部分会从 0 方向被截断。
例子
#include <stdio.h>
int main() {
float heads;
while(1) {
printf("Please enter a number: ");
scanf("%d", &heads);
printf("%f\r\n", heads);
}
}结果:
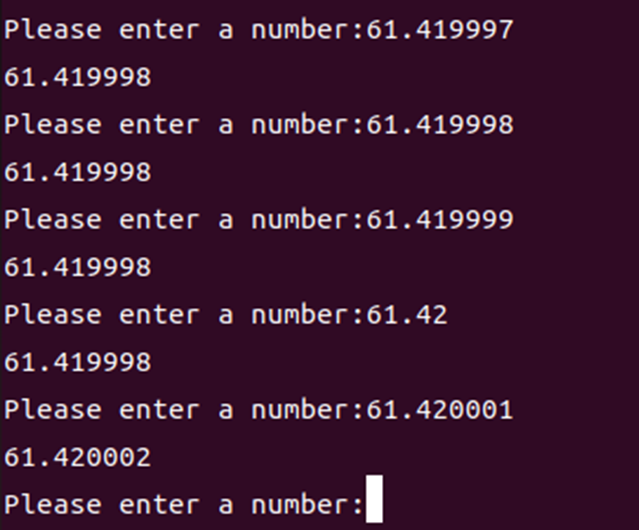
原因:float 类型的最小精度使得它只能表示到这里的 0.000004
数据的宽度和存储#
C语言中数值数据类型的宽度#
- 不同机器同一类型宽度可能会不同。
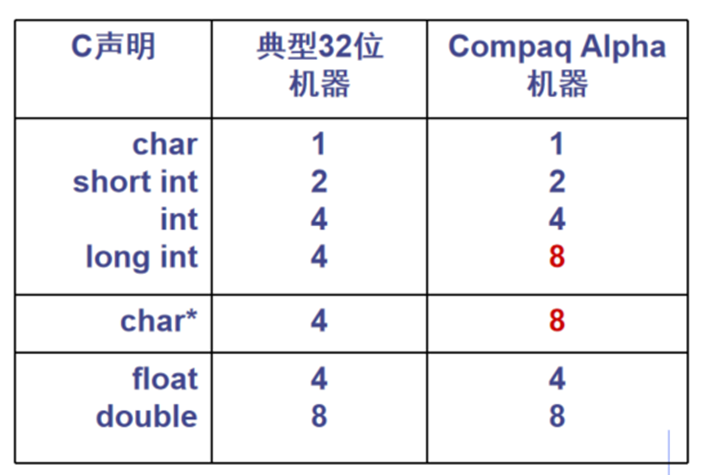
注:Compaq Alpha 是 64 位机
C语言中类型转换顺序(比较重要)#
顺序从大到小:
unsigned long long <- long long <- unsigned <- int <- (unsigned)char, short
例子
#include <stdio.h>
int main()
{
unsigned int a = 1;
unsigned short b = 1;
char c = -1;
int d;
d = (a > c) ? 1 : 0;
// c 的码点为 neg(0000 0001) = 1111 1111, 符号扩展后升级为 int
// 但是 a 是 unsigned int,于是整个比较按照无符号数比较,就变成了 1 > 4294967295
printf("%d\n", d);
d = (b > c) ? 1 : 0;
// 所有小于 int 的整数类型(包括 char)都会被提升为 int 型,b 和 c被转换为了 int 型下的 1 和 -1
printf("%d\n", d);
}
// Result: 0 1C 语言中的运算#
按位逻辑运算和逻辑运算#
- 按位逻辑运算:
&|~^对位串实现 掩码 操作或其他处理 - 逻辑运算:
&&||!
移位运算#
>> << 用于提取部分信息、扩大或缩小数值的 2/4/8 倍
例子
y >> 8; //提取 y 的高位数据位扩展运算和位截断运算#
无。类型转换时自动进行。
例子 1
short si = -32768; // si = -32768; 0x8000
unsigned short usi = si; // usi = 32768; 0x8000
int i = si; // i = -32768; 0xffff8000
unsigned ui = usi; // i = 32768; 0x00008000例子 2
int i = 32768; // i = 0x00008000
short si = (short)i; // si = 0x8000
int j = si; // j = 0xffff8000
// Result: j != si整数算术运算#
- C 语言整数实现与汇编语言的差异,此处略。
- 无符号数加法溢出判断
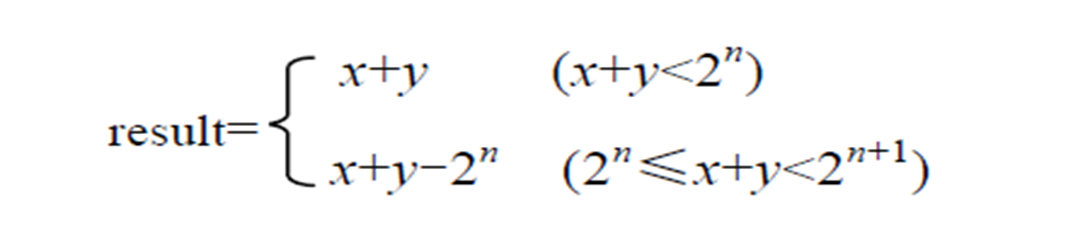
发生溢出时,一定满足:**result < x && result < y**int uadd_ok(unsigned x, unsigned y) {
unsigned sum = x + y;
return su >= x;
}- 有符号数加法溢出判断
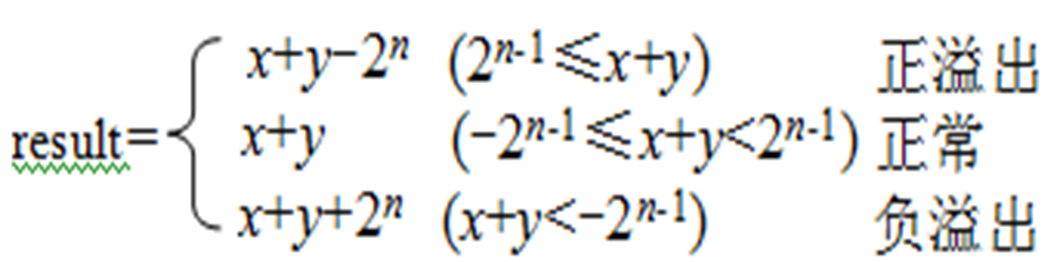
int tadd_ok(int x, int y) {
int sum = x+y;
int neg_over = x < 0 && y < 0 && sum >= 0;
int pos_over = x >= 0 && y >= 0 && sum < 0;
return !neg_over && !pos_over;
} 例题 以下程序判断相减有没有问题?
int tsub_ok(int x, int y) {
return tadd_ok(x, -y);
}
// y = 0x80000000 时出错-
整数的乘运算
在 C 语言中,参加运算的数类型必须一致,如果不一致会转换为一致再计算。
例题 以下程序存在什么漏洞
int copy_array(int *array, int count)
{
int i;
/* 在堆区申请一块内存 */
int *myarray = (int *) malloc(count*sizeof(int));
if (myarray == NULL)
return -1;
for (i = 0; i < count; i++)
myarray[i] = array[i];
return count;
}
// count * sizeof(int) 可能会溢出,造成数组越界访问- 整数的除法运算
// Code segement I
int a = 0x80000000;
int b = a / -1;
printf("%d\n", b);
// Result: -2147483648
// Code segement II
int a = 0x80000000;
int b = -1;
int c = a / b;
printf("%d\n", c);
// Result: "Floating point exception"浮点数的运算#
- 浮点数的除 0 运算
#include <stdio.h>
int main()
{
int a = 1;
int b = 0;
printf("Division by zero: %d\n", a/b);
return 0;
}
// Result: 整数除 0 发生异常!然而浮点数有表示无穷大的码点:#include <stdio.h>
int main()
{
double a = 1.0;
double b = -1.0;
double c = 0.0;
printf("Division by zero: %f %f\n", a/c, b/c);
return 0;
}
// Result: 无穷大-
浮点数的比较运算
以下列表判断是否永真
| 表达式 | 结果 |
|---|---|
| x == (int)(float) x | 否 |
| x == (int)(double) x | 是 |
| f == (float)(double) f | 是 |
| d == (float) d | 否 |
| f == -(-f); | 是 |
| 2/3 == 2/3.0 | 否 |
| d < 0.0 ⇒((d\2) < 0.0) | 是 |
| d > f ⇒-f > -d | 是 |
| d \ d >= 0.0 | 是 |
| x\x>=0 | 否 |
| (d+f)-d == f | 否 |
选择语句的机器级表示#
if-else 语句的机器级表示#
例子
#include <stdio.h>
int main()
{
int flag;
int x = 3;
int y = -1;
if (x > 0 || y > 0)
flag = 1;
else
flag = 0;
printf("flag = %d \n", flag);
return 0;
}对应的汇编代码:
# a.c:5: int x = 3;
movl $3, -8(%rbp) #, x
# a.c:6: int y = -1;
movl $-1, -4(%rbp) #, y
# a.c:7: if (x > 0 || y > 0)
cmpl $0, -8(%rbp) #, x
jg .L2 #,
# a.c:7: if (x > 0 || y > 0)
cmpl $0, -4(%rbp) #, y
jle .L3 #,
.L2:
# a.c:8: flag = 1;
movl $1, -12(%rbp) #, flag
jmp .L4 #
.L3:
# a.c:10: flag = 0;
movl $0, -12(%rbp) #, flag
.L4:
# a.c:11: printf("flag = %d \n", flag);
movl -12(%rbp), %eax # flag, tmp84
movl %eax, %esi # tmp84,
leaq .LC0(%rip), %rax #, tmp85
movq %rax, %rdi # tmp85,
movl $0, %eax #,
call printf@PLT #switch 的机器级表示#
例子 1
#include <stdio.h>
int main()
{
int x = 3;
int y = -1;
int z;
int i = 1;
char c;
c = getchar();
switch (c) {
case '+':
case 'a':
z = x + y;
break;
case '-':
case 's':
z = x - y;
break;
default:
z = 0;
}
printf(" %d %c %d = %d \n", x, c, y, z);
return 0;
}对应的汇编代码:
# a.c:4: int x = 3;
movl $3, -12(%rbp) #, x
# a.c:5: int y = -1;
movl $-1, -8(%rbp) #, y
# a.c:7: int i = 1;
movl $1, -4(%rbp) #, i
# a.c:9: c = getchar();
call getchar@PLT #
# a.c:9: c = getchar();
movb %al, -17(%rbp) # _1, c
# a.c:10: switch (c) {
movsbl -17(%rbp), %eax # c, _2
cmpl $115, %eax #, _2
je .L2 #,
cmpl $115, %eax #, _2
jg .L3 #,
cmpl $97, %eax #, _2
je .L4 #,
cmpl $97, %eax #, _2
jg .L3 #,
cmpl $43, %eax #, _2
je .L4 #,
cmpl $45, %eax #, _2
je .L2 #,
jmp .L3 #
.L4:
# a.c:13: z = x + y;
movl -12(%rbp), %edx # x, tmp91
movl -8(%rbp), %eax # y, tmp92
addl %edx, %eax # tmp91, tmp90
movl %eax, -16(%rbp) # tmp90, z
# a.c:14: break;
jmp .L5 #
.L2:
# a.c:17: z = x - y;
movl -12(%rbp), %eax # x, tmp96
subl -8(%rbp), %eax # y, tmp95
movl %eax, -16(%rbp) # tmp95, z
# a.c:18: break;
jmp .L5 #
.L3:
# a.c:20: z = 0;
movl $0, -16(%rbp) #, z
.L5:
# a.c:22: printf(" %d %c %d = %d \n", x, c, y, z);
movsbl -17(%rbp), %edx # c, _3
movl -16(%rbp), %esi # z, tmp97
movl -8(%rbp), %ecx # y, tmp98
movl -12(%rbp), %eax # x, tmp99
movl %esi, %r8d # tmp97,
movl %eax, %esi # tmp99,
leaq .LC0(%rip), %rax #, tmp100
movq %rax, %rdi # tmp100,
movl $0, %eax #,
call printf@PLT #例子 2
#include <stdio.h>
int main()
{
int result = 0;
int a = 12;
int c = 0;
int b = 10;
switch (a)
{
case 15:
c = b &0x0f;
case 10:
result = c + 50;
break;
case 12:
case 17:
result = b + 50;
break;
case 14:
result = b;
break;
default:
result = a;
}
printf("%d\n", result);
return 0;
}以下是对应的汇编代码:
# a.c:4: int result = 0;
movl $0, -16(%rbp) #, result
# a.c:5: int a = 12;
movl $12, -8(%rbp) #, a
# a.c:6: int c = 0;
movl $0, -12(%rbp) #, c
# a.c:7: int b = 10;
movl $10, -4(%rbp) #, b
# a.c:8: switch (a)
movl -8(%rbp), %eax # a, tmp85
subl $10, %eax #, tmp84
cmpl $7, %eax #, tmp84
ja .L2 #,
movl %eax, %eax # tmp84, tmp86
leaq 0(,%rax,4), %rdx #, tmp87
leaq .L4(%rip), %rax #, tmp88
movl (%rdx,%rax), %eax #, tmp89
cltq
leaq .L4(%rip), %rdx #, tmp92
addq %rdx, %rax # tmp92, tmp91
notrack jmp *%rax # tmp91
.section .rodata
.align 4
.align 4
.L4:
.long .L7-.L4
.long .L2-.L4
.long .L3-.L4
.long .L2-.L4
.long .L6-.L4
.long .L5-.L4
.long .L2-.L4
.long .L3-.L4
.text
.L5:
# a.c:11: c = b &0x0f;
movl -4(%rbp), %eax # b, tmp96
andl $15, %eax #, tmp95
movl %eax, -12(%rbp) # tmp95, c
.L7:
# a.c:13: result = c + 50;
movl -12(%rbp), %eax # c, tmp100
addl $50, %eax #, tmp99
movl %eax, -16(%rbp) # tmp99, result
# a.c:14: break;
jmp .L8 #
.L3:
# a.c:17: result = b + 50;
movl -4(%rbp), %eax # b, tmp104
addl $50, %eax #, tmp103
movl %eax, -16(%rbp) # tmp103, result
# a.c:18: break;
jmp .L8 #
.L6:
# a.c:20: result = b;
movl -4(%rbp), %eax # b, tmp105
movl %eax, -16(%rbp) # tmp105, result
# a.c:21: break;
jmp .L8 #
.L2:
# a.c:23: result = a;
movl -8(%rbp), %eax # a, tmp106
movl %eax, -16(%rbp) # tmp106, result
.L8:
# a.c:25: printf("%d\n", result);
movl -16(%rbp), %eax # result, tmp107
movl %eax, %esi # tmp107,
leaq .LC0(%rip), %rax #, tmp108
movq %rax, %rdi # tmp108,
movl $0, %eax #,
call printf@PLT #以上switch语句运行时借助了 跳表 进行实现。
条件表达式的机器级表示#
例子
#include <stdio.h>
int main()
{
int a;
int x;
scanf("%d", &a);
x = a > 0 ? a : a + 100;
printf("x = %d \n", x);
return 0;
}对应的汇编代码:
# a.c:7: x = a > 0 ? a : a + 100;
movl -16(%rbp), %eax # a, a.1_1
# a.c:7: x = a > 0 ? a : a + 100;
testl %eax, %eax # a.1_1
jg .L2 #,
# a.c:7: x = a > 0 ? a : a + 100;
movl -16(%rbp), %eax # a, a.2_2
# a.c:7: x = a > 0 ? a : a + 100;
addl $100, %eax #, iftmp.0_3
jmp .L3 #
.L2:
# a.c:7: x = a > 0 ? a : a + 100;
movl -16(%rbp), %eax # a, iftmp.0_3
.L3:
# a.c:7: x = a > 0 ? a : a + 100;
movl %eax, -12(%rbp) # iftmp.0_3, x循环结构的机器级表示#
do-while 循环#
#include <stdio.h>
int main()
{
int i = 1;
int result = 0;
do
{
result += i;
i++;
}
while (i <= 10);
printf("result = %d \n", result);
return 0;
}对应的汇编代码:
.L2:
# a.c:8: result += i;
movl -8(%rbp), %eax # i, tmp84
addl %eax, -4(%rbp) # tmp84, result
# a.c:9: i++;
addl $1, -8(%rbp) #, i
# a.c:11: while (i <= 10);
cmpl $10, -8(%rbp) #, i
jle .L2 #,while 循环#
#include <stdio.h>
int main()
{
int i = 1;
int n = 100;
int result = 0;
while (i <= n)
{
result += i;
i++;
}
printf("result = %d \n", result);
return 0;
}对应的汇编代码:
# a.c:7: while (i <= n)
jmp .L2 #
.L3:
# a.c:9: result += i;
movl -12(%rbp), %eax # i, tmp84
addl %eax, -8(%rbp) # tmp84, result
# a.c:10: i++;
addl $1, -12(%rbp) #, i
.L2:
# a.c:7: while (i <= n)
movl -12(%rbp), %eax # i, tmp85
cmpl -4(%rbp), %eax # n, tmp85
jle .L3 #,for 循环#
例子 1
#include <stdio.h>
int main()
{
int n = 100;
int result = 0;
for (int i = 1; i <= n; i++)
result += i;
printf("result = %d \n", result);
return 0;
}对应的汇编代码:
# a.c:6: for (int i = 1; i <= n; i++)
movl $1, -8(%rbp) #, i
# a.c:6: for (int i = 1; i <= n; i++)
jmp .L2 #
.L3:
# a.c:7: result += i;
movl -8(%rbp), %eax # i, tmp84
addl %eax, -12(%rbp) # tmp84, result
# a.c:6: for (int i = 1; i <= n; i++)
addl $1, -8(%rbp) #, i
.L2:
# a.c:6: for (int i = 1; i <= n; i++)
movl -8(%rbp), %eax # i, tmp85
cmpl -4(%rbp), %eax # n, tmp85
jle .L3 #,例子 2
#include <stdio.h>
int main()
{
char buf1[20];
char buf2[20];
int i;
scanf("%s", buf1);
for (i = 0; i < 20; i++)
buf2[i] = buf1[i];
printf("%s\n", buf2);
return 0;
}对应的汇编代码:
# a.c:8: for (i = 0; i < 20; i++)
movl $0, -68(%rbp) #, i
# a.c:8: for (i = 0; i < 20; i++)
jmp .L2 #
.L3:
# a.c:9: buf2[i] = buf1[i];
movl -68(%rbp), %eax # i, tmp88
cltq
movzbl -64(%rbp,%rax), %edx # buf1[i_2], _1
# a.c:9: buf2[i] = buf1[i];
movl -68(%rbp), %eax # i, tmp90
cltq
movb %dl, -32(%rbp,%rax) # _1, buf2[i_2]
# a.c:8: for (i = 0; i < 20; i++)
addl $1, -68(%rbp) #, i
.L2:
# a.c:8: for (i = 0; i < 20; i++)
cmpl $19, -68(%rbp) #, i
jle .L3 #,事实上,汇编语言是比较好实现 do-while 结构的
而 while 其实是相对不那么好实现的
for 循环的结构看起来就是在判断的前面、 while 的函数段后面加了两行(例如 i++ )
编译优化#
在 gcc 编译程序的时候,可以选择 -O0 -O1 -O2 -O3 四个等级,对应等级是优化水平。O0 即完全不优化。
循环结构与递归的比较#
递归求和:
#include <stdio.h>
int iter_sum(int n)
{
int result;
if (n <= 0)
result = 0;
else
result = n + iter_sum(n - 1);
return result;
}
int main()
{
int sum = iter_sum(10);
printf("%d\n", sum);
return 0;
}对应的汇编程序:
iter_sum:
# a.c:5: if (n <= 0)
cmpl $0, -20(%rbp) #, n
jg .L2 #,
# a.c:6: result = 0;
movl $0, -4(%rbp) #, result
jmp .L3 #
.L2:
# a.c:8: result = n + iter_sum(n - 1);
movl -20(%rbp), %eax # n, tmp86
subl $1, %eax #, _1
movl %eax, %edi # _1,
call iter_sum #
# a.c:8: result = n + iter_sum(n - 1);
movl -20(%rbp), %edx # n, tmp90
addl %edx, %eax # tmp90, tmp89
movl %eax, -4(%rbp) # tmp89, result
.L3:
# a.c:9: return result;
movl -4(%rbp), %eax # result, _10
main:
# a.c:13: int sum = iter_sum(10);
movl $10, %edi #,
call iter_sum #
movl %eax, -4(%rbp) # tmp84, sum非递归求和:
#include <stdio.h>
int main()
{
int n = 10;
int i;
int result = 0;
for (i=1; i <= n; i++)
result += i;
printf("%d\n", result);
return 0;
}对应的汇编代码:
# a.c:7: for (i=1; i <= n; i++)
movl $1, -12(%rbp) #, i
# a.c:7: for (i=1; i <= n; i++)
jmp .L2 #
.L3:
# a.c:8: result += i;
movl -12(%rbp), %eax # i, tmp84
addl %eax, -8(%rbp) # tmp84, result
# a.c:7: for (i=1; i <= n; i++)
addl $1, -12(%rbp) #, i
.L2:
# a.c:7: for (i=1; i <= n; i++)
movl -12(%rbp), %eax # i, tmp85
cmpl -4(%rbp), %eax # n, tmp85
jle .L3 #,可见非递归程序没有用到 call 命令,减少了调用、返回、保护现场三个步骤,并且没有使用栈帧。因此,为了提高程序的性能,应该尽量用非递归方式实现功能。
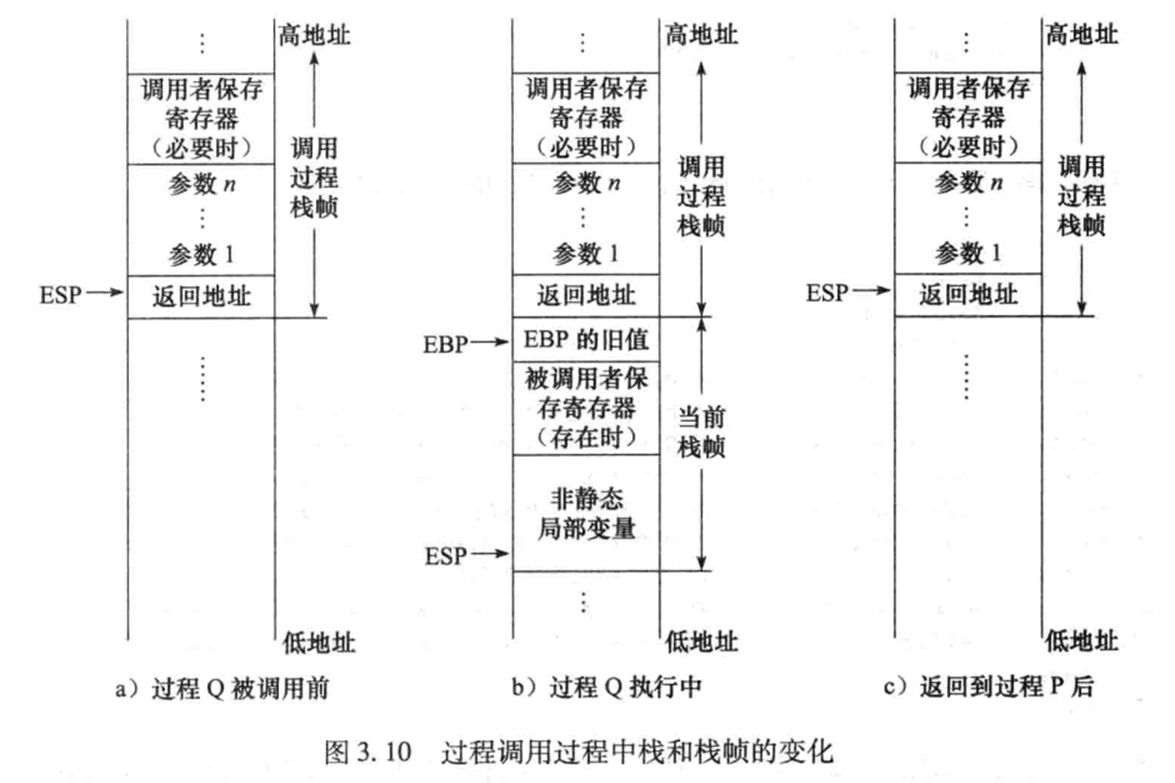
过程调用的机器级表示#
- 过程调用的运行机理:
例子
#include <stdio.h>
int fadd(int x, int y)
{
int u,v,w;
u = x + 10;
v = y + 25;
w = u + v;
return w;
}
int main()
{
int a = 100; // 0x 64
int b = 200; // 0x C8
int sum = 0;
sum = fadd(a, b);
printf("%d\n", sum);
return 0;
}对应的一些汇编代码:
Dump of assembler code for function fadd:
3 {
0x5655619d <+0>: push %ebp # 保护现场,这里只用保护ebp
0x5655619e <+1>: mov %esp,%ebp # 使用ebp,保存进入子程序时,保护现场后堆栈段的基址。EBP = 0xffffd160
0x565561a0 <+3>: sub $0x10,%esp # 为局部变量分配空间。三个局部变量,总长度为12个字节。为了对齐,分配了16个字节的空间。
0x565561a3 <+6>: call 0x56556236 <__x86.get_pc_thunk.ax>
0x565561a8 <+11>: add $0x2e30,%eax
4 int u,v,w;
5 u = x + 10;
0x565561ad <+16>: mov 0x8(%ebp),%eax # 源操作数使用了参数x
0x565561b0 <+19>: add $0xa,%eax
0x565561b3 <+22>: mov %eax,-0xc(%ebp) # 目的操作数使用了局部变量x
6 v = y + 25;
0x565561b6 <+25>: mov 0xc(%ebp),%eax
0x565561b9 <+28>: add $0x19,%eax
0x565561bc <+31>: mov %eax,-0x8(%ebp)
7 w = u + v;
0x565561bf <+34>: mov -0xc(%ebp),%edx
0x565561c2 <+37>: mov -0x8(%ebp),%eax
0x565561c5 <+40>: add %edx,%eax
0x565561c7 <+42>: mov %eax,-0x4(%ebp)
8 return w;
0x565561ca <+45>: mov -0x4(%ebp),%eax # 将返回值送入EAX。通过EAX返回子程序的返回值。
9 }
0x565561cd <+48>: leave # leave指令,等价于
# mov %ebp, %esp
# pop %ebp
# 即还原ESP、EBP
0x565561ce <+49>: ret # ret,出栈到EIP
Dump of assembler code for function main:
11 {
0x565561cf <+0>: lea 0x4(%esp),%ecx
0x565561d3 <+4>: and $0xfffffff0,%esp
0x565561d6 <+7>: push -0x4(%ecx)
0x565561d9 <+10>: push %ebp
0x565561da <+11>: mov %esp,%ebp
0x565561dc <+13>: push %ebx
0x565561dd <+14>: push %ecx
0x565561de <+15>: sub $0x10,%esp
0x565561e1 <+18>: call 0x565560a0 <__x86.get_pc_thunk.bx>
0x565561e6 <+23>: add $0x2df2,%ebx
12 int a = 100; // 0x 64
0x565561ec <+29>: movl $0x64,-0x14(%ebp)
13 int b = 200; // 0x C8
0x565561f3 <+36>: movl $0xc8,-0x10(%ebp)
14 int sum = 0;
0x565561fa <+43>: movl $0x0,-0xc(%ebp)
15 sum = fadd(a, b);
0x56556201 <+50>: push -0x10(%ebp)
0x56556204 <+53>: push -0x14(%ebp)
0x56556207 <+56>: call 0x5655619d <fadd>
0x5655620c <+61>: add $0x8,%esp # 出栈参数x、y
0x5655620f <+64>: mov %eax,-0xc(%ebp)在 main 第一行处执行:
(gdb) p/x $esp
$2 = 0xffffce20然后执行
(gdb) x/16 0xffffce20 - 48
0xffffcdf0: 0x00000000 0x00000000 0x01000000 0x0000000b
0xffffce00: 0xf7fc4560 0x00000000 0xf7d9b4be 0xf7fa9054
0xffffce10: 0xf7fbe4a0 0xf7fd6f20 0xf7d9b4be 0x565561e6 <- main入口
0xffffce20: 0xffffce60 0xf7fbe66c 0xf7fbeb20 0x00000001接着执行到 fadd:
fadd (x=100, y=200) at a.c:3
3 {
(gdb) p/x $eip
$2 = 0x5655619d这时:
(gdb) p/x $esp
$3 = 0xffffce14
(gdb) x/16 0xffffce20 - 48
0xffffcdf0: 0x00000000 0x00000000 0x01000000 0x0000000b
0xffffce00: 0xf7fc4560 0x00000000 0xf7d9b4be 0xf7fa9054
0xffffce10: 0xf7fbe4a0 0x5655620c 0x00000064 0x000000c8
^ main函数返回点 ^ a ^ b
0xffffce20: 0xffffce60 0x00000064 0x000000c8 0x00000000由此可见,栈帧和局部变量在栈内被很好地保护了。
调用时栈和栈帧的变化如下图:
局部变量#
- 子程序开始执行时,在堆栈中分配局部变量空间。
- 局部变量在子程序栈帧中
- 子程序退出前,会释放局部变量的空间。因此,局部变量的作用域和生存空间只在子程序中。
详情可以参考上面这一例汇编内的注释。
按值传递参数和按地址传递参数#
- 基本的形参和实参概念
- 按值传递:传递变量值;按地址传递:传递变量地址(指针)。
- 按地址传递的时候记得间接寻址,直接修改地址参数是啥用都没有的。
例子 按值传递参数
#include <stdio.h>
void swap(int x, int y)
{
int t = x;
x = y;
y = t;
}
int main()
{
int a = 15;
int b = 22;
printf("a=%d b=%d\n", a, b);
swap(a, b);
printf("a=%d b=%d\n", a, b);
return 0;
}汇编片段:
main:
# a.c:13: swap(a, b);
movl -4(%rbp), %edx # b, tmp87
movl -8(%rbp), %eax # a, tmp88
movl %edx, %esi # tmp87,
movl %eax, %edi # tmp88,
call swap #
swap:
movl %edi, -20(%rbp) # x, x
movl %esi, -24(%rbp) # y, y
# a.c:4: int t = x;
movl -20(%rbp), %eax # x, tmp82
movl %eax, -4(%rbp) # tmp82, t
# a.c:5: x = y;
movl -24(%rbp), %eax # y, tmp83
movl %eax, -20(%rbp) # tmp83, x
# a.c:6: y = t;
movl -4(%rbp), %eax # t, tmp84
movl %eax, -24(%rbp) # tmp84, y例子 按地址传递参数
#include <stdio.h>
void swap(int* x, int* y)
{
int t = *x;
*x = *y;
*y = t;
}
int main()
{
int a = 15;
int b = 22;
printf("a=%d b=%d\n", a, b);
swap(&a, &b);
printf("a=%d b=%d\n", a, b);
return 0;
}汇编片段:
main:
# a.c:13: swap(&a, &b);
leaq -12(%rbp), %rdx #, tmp89
leaq -16(%rbp), %rax #, tmp90
movq %rdx, %rsi # tmp89,
movq %rax, %rdi # tmp90,
call swap #
swap:
movq %rdi, -24(%rbp) # x, x
movq %rsi, -32(%rbp) # y, y
# a.c:4: int t = *x;
movq -24(%rbp), %rax # x, tmp83
movl (%rax), %eax # *x_3(D), tmp84
movl %eax, -4(%rbp) # tmp84, t
# a.c:5: *x = *y;
movq -32(%rbp), %rax # y, tmp85
movl (%rax), %edx # *y_5(D), _1
# a.c:5: *x = *y;
movq -24(%rbp), %rax # x, tmp86
movl %edx, (%rax) # _1, *x_3(D)
# a.c:6: *y = t;
movq -32(%rbp), %rax # y, tmp87
movl -4(%rbp), %edx # t, tmp88
movl %edx, (%rax) # tmp88, *y_5(D)上述片段先将地址取出,再利用寄存器间接寻址最终修改了内存中的原数据。
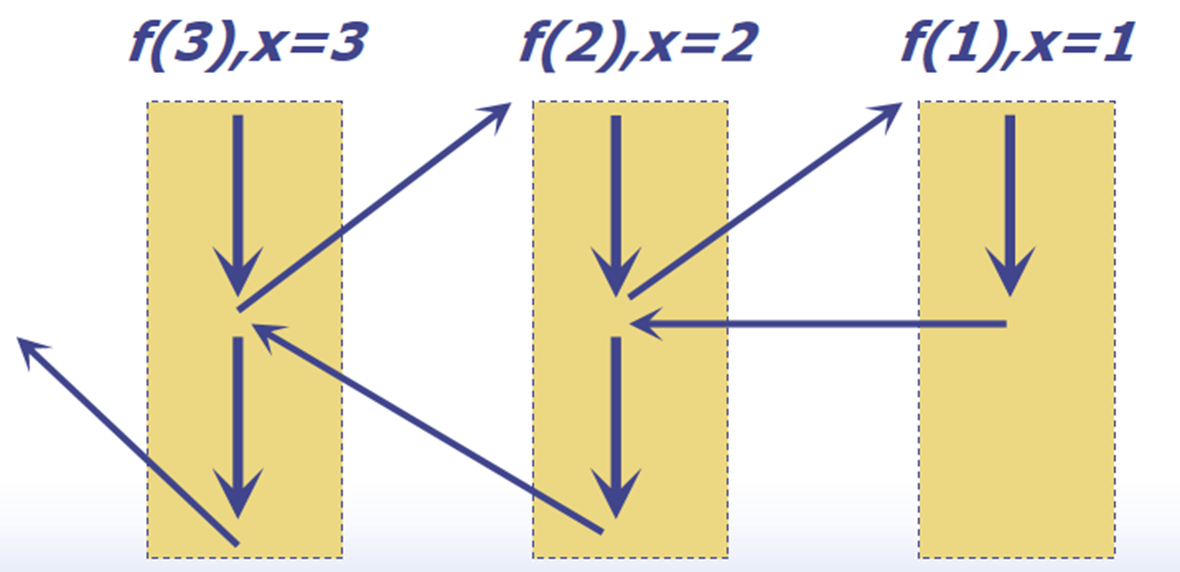
递归过程调用#
前文已经有一个例子了,这里再举一个。
#include <stdio.h>
int f(int x)
{
if (x==1)
return 1;
return x*f(x-1);
}
int main()
{
printf("%d\n",f(5));
return 0;
}对应的汇编代码:
f:
movl %edi, -4(%rbp) # x, x
# a.c:4: if (x==1)
cmpl $1, -4(%rbp) #, x
jne .L2 #,
# a.c:5: return 1;
movl $1, %eax #, _3
jmp .L3 #
.L2:
# a.c:6: return x*f(x-1);
movl -4(%rbp), %eax # x, tmp86
subl $1, %eax #, _1
movl %eax, %edi # _1,
call f #
# a.c:6: return x*f(x-1);
imull -4(%rbp), %eax # x, _3
.L3:
# a.c:7: }
leave
.cfi_def_cfa 7, 8
ret
main:
# a.c:10: printf("%d\n",f(5));
movl $5, %edi #,
call f #
movl %eax, %esi # _1,
leaq .LC0(%rip), %rax #, tmp85
movq %rax, %rdi # tmp85,
movl $0, %eax #,
call printf@PLT #递归调用示意图:
其实相关原理 C 语言已经都学过了,这里看懂汇编即可。